mysql 索引及优化
什么是索引
- 索引类似目录,在mysql中数据是存在文件中的,那么索引其实就是一个指针,通过找到这个索引从而找到整条数据的文件位置,以及数据的偏移量(在文件中数据在哪个位置上)
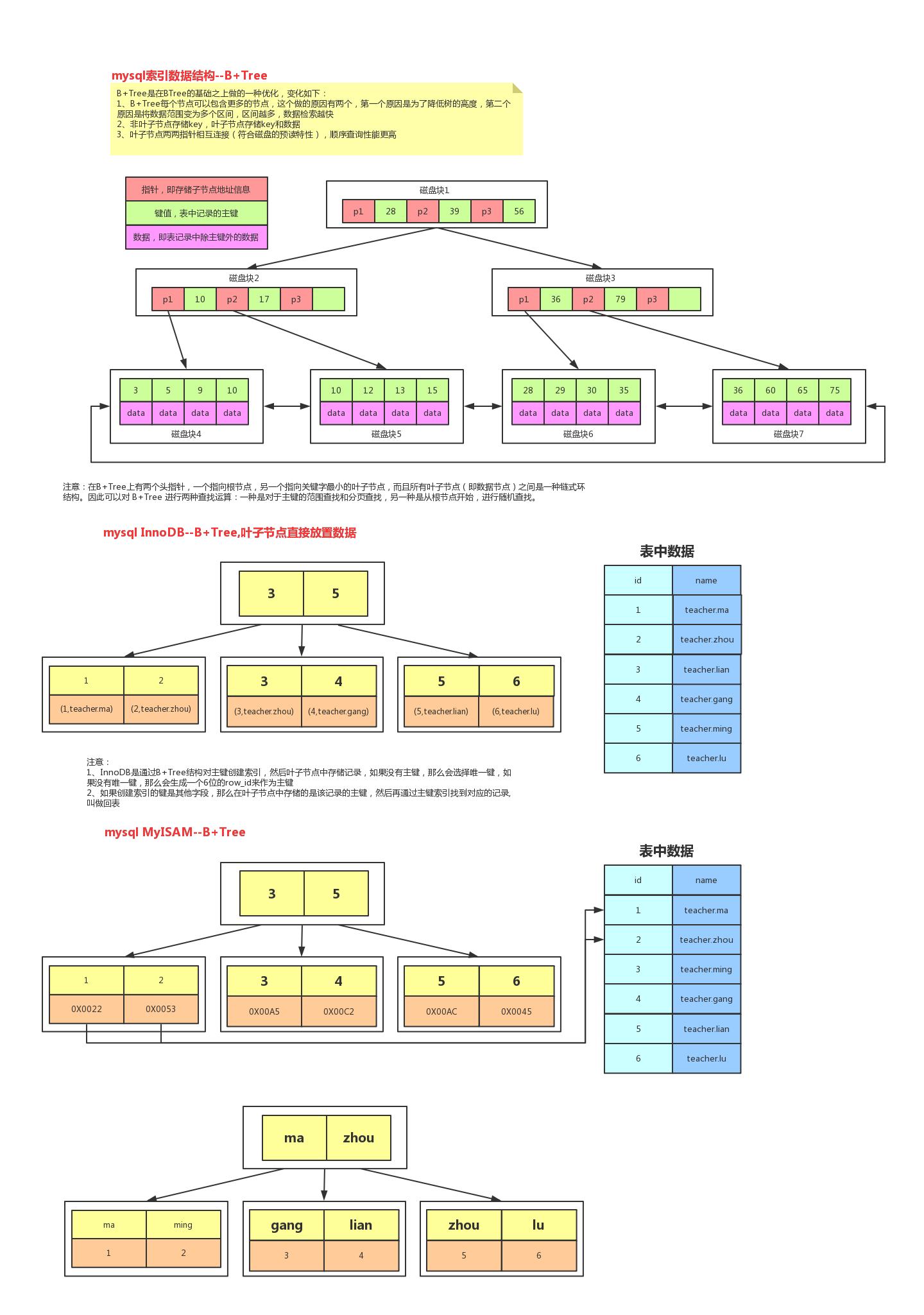
为什么innodb 要使用b+树而不使用其他数据结构?
- 如二叉/红黑树 都只有2个叶子节点会造成树高过高的情况,增加查询和插入的性能损失
- 如下图所示p1,p2,p3代表了索引,比如每个索引占用的是10个字节的数据 16k 就可以查询到 16 * 1024 /10 的字节数,两层就是再开个平方这种,mysql 就支持千万级别的查询
索引的匹配方式
| 匹配方式 |
说明 |
| 全值匹配 |
和复合索引中的所有列进行匹配,也就是where 里包含了复合索引中的所有列如(id,name)where id = xx and name = xxx |
| 最左前缀 |
和复合索引中左边的索引匹配如索引为(id,name) where id = xx |
| 匹配列前缀 |
只匹配列的前面几个字符 如 like ‘abc%’ 前缀索引可以非常大程度的优化索引的大小,一般使用前缀索引的前7位 作为索引就可以比较均衡并有效的利用性能,具体以字段含义为准。 |
| 匹配范围值 |
where age > 10 |
| 精确匹配到某一列 并范围匹配到另外1列 |
where name = xx and age > 10 |
| 覆盖查询 |
当查询的内容都是索引里的内容,这样就不需要查询data了 如index(name,age) select age from t where name = xx |
对于普通索引
- 普通索引的叶子节点保存了主键索引的地址,然后再由普通索引指向具体的data数据
优化要点
排序时尽量使用索引
- 这样可以把随机io 变成顺序io
- 因为在插入数据的时候就给你排好序了
- 但是如果对两个字段进行索引排序时 如
add index(a asc) ;
add index (b asc);
-- 但是排序时使用的是
select x from t order by a desc b asc; --这种情况下无法利用索引性能因为索引上时是都是正序,而实际排序时需要一个字段正序 一个字段倒序 mysql 无法排
join 时尽量join 重复值多的数
- 因为索引里相同的索引值是连续的,可以减少io 查找的难度。
union all, or ,in 都能使用索引 但是推荐使用in
- 以下是三种写法执行相同效果的代码

强制类型转换 会使索引失效
-- 如果phone为varchar 但是等号后面是数字 mysql 解释器其实是认识的,但是他会做隐式的类型转换这种情况下 会使索引失效
select * from t where phone = 123456;
更新频繁,数据区分度不高字段不宜建立索引
- 因为索引值会存在合并和分裂的情况下,会改变树的结构。
创建索引的列尽量不要为null
如果明确只有1条数据返回,使用limit 1进行查询
避免3张表以上的join
join 的三种方式
1. Simple Nested-Loop Join
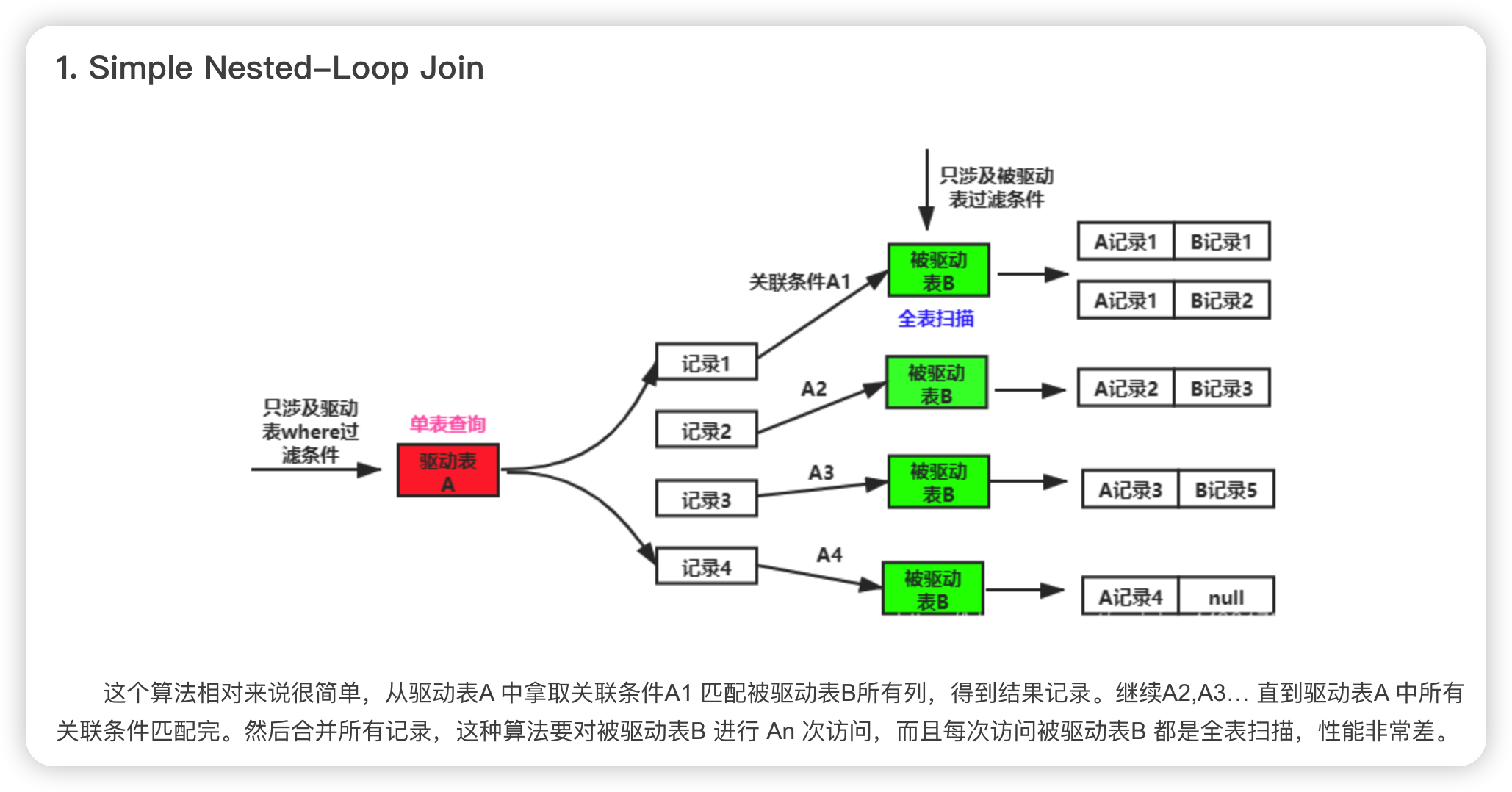
- 该方法等于一个双重for 循环性能最差
- 一般情况下mysql 不会使用这种方式
2. Index Nested-Loop Join
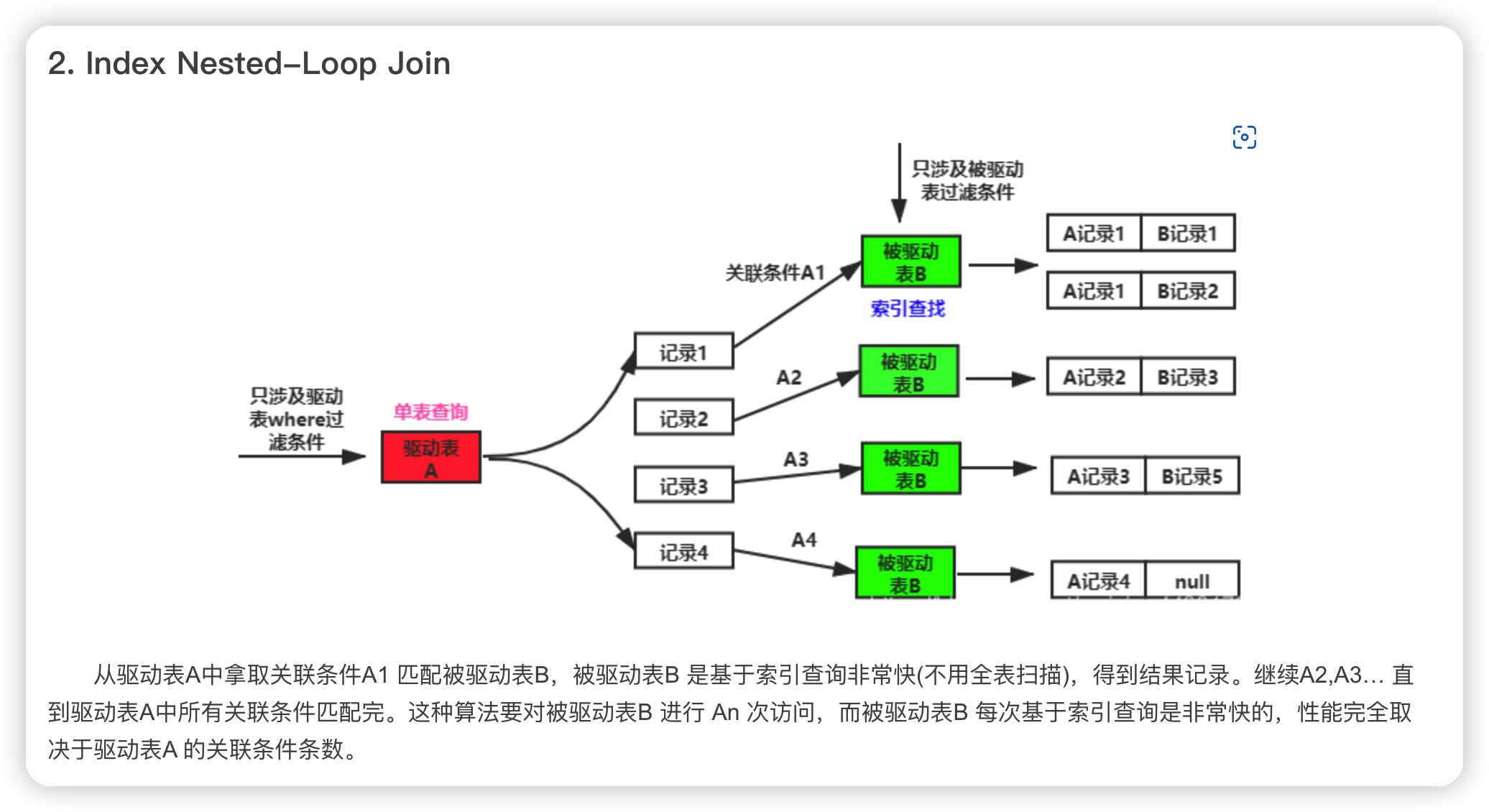
- 在有索引的情况下,MySQL 会尝试去使用 Index Nested-Loop Join 算法。
3.Block Nested-Loop Join
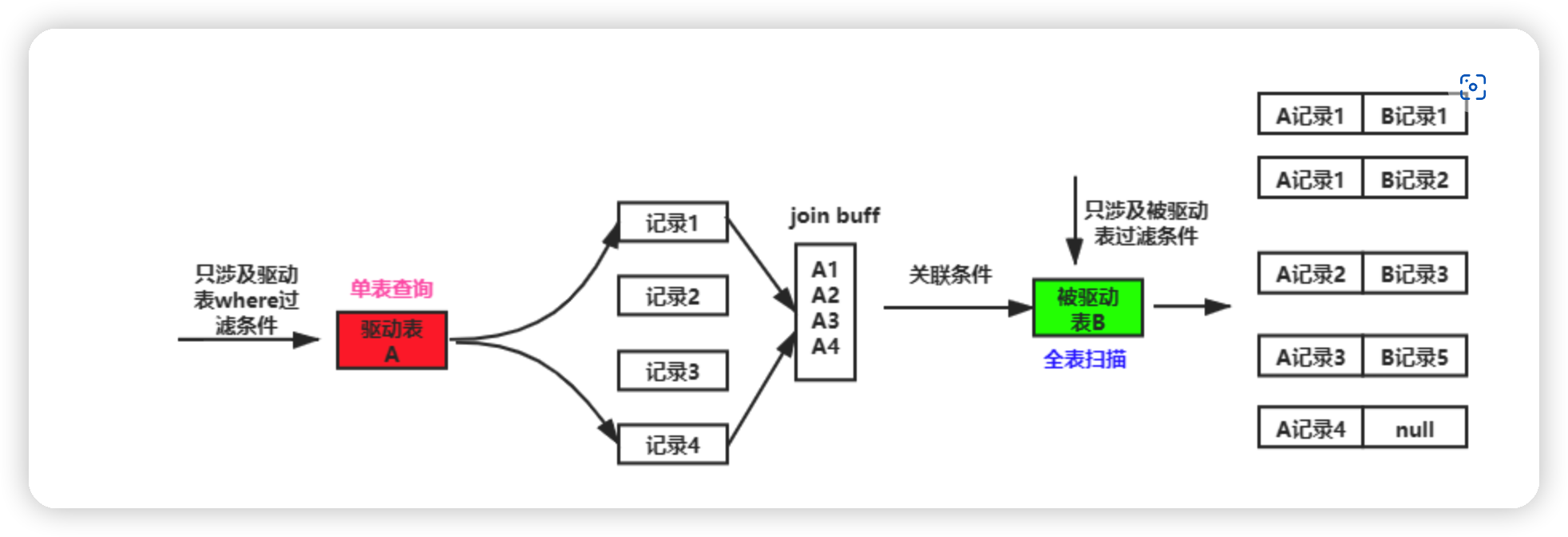
- 在有些情况下,可能 Join 的列就是没有索引,那么这时 MySQL 的选择绝对不会是最先介绍的 Simple Nested-Loop Join 算法,而是会优先使用Block Nested-Loop Join 的算法。